RNN부터 GPT까지 이해해보기
GPT를 이해하기 위해 필요한 것들. RNN 구조부터 GPT까지 차근차근 이해해보기
목차
GPT 구조에 대해 빠르게 이해하기 위한 방법
open ai의 chat gpt가 발표되기 이전에도 transformer가 가진 강력함에 대해서는 많은 이야기를 들었었다. 당시에도 주변 사람들에게 물어보며 핵심적인 구조인 transformer와 self-attention에 대해 이해해보려고 했지만 성공하지는 못했었다. 지금 생각해보면 이해하기에는 내가 가진 지식이 너무 부족했던 것 같다. 결국에 gpt를 빨리 이해하기 위해서는 필요한 사전지식을 모두 갖추고 있어야 할 것이다. cs182 강의의 10장부터 13장까지가 RNN부터 GPT까지를 모두 다루고 있어 큰 도움이 되었다. 이글은 해당 강의들에 대한 요약 정리한 것이다. 강의 내용을 다시 되새기는 것에 목적이 있다. cs182 강의는 딥러닝을 처음 접한 사람보다는 조금 익숙한 사람들이 다시 정리하기 좋은 강의라고 생각된다.
전반적인 강의 흐름
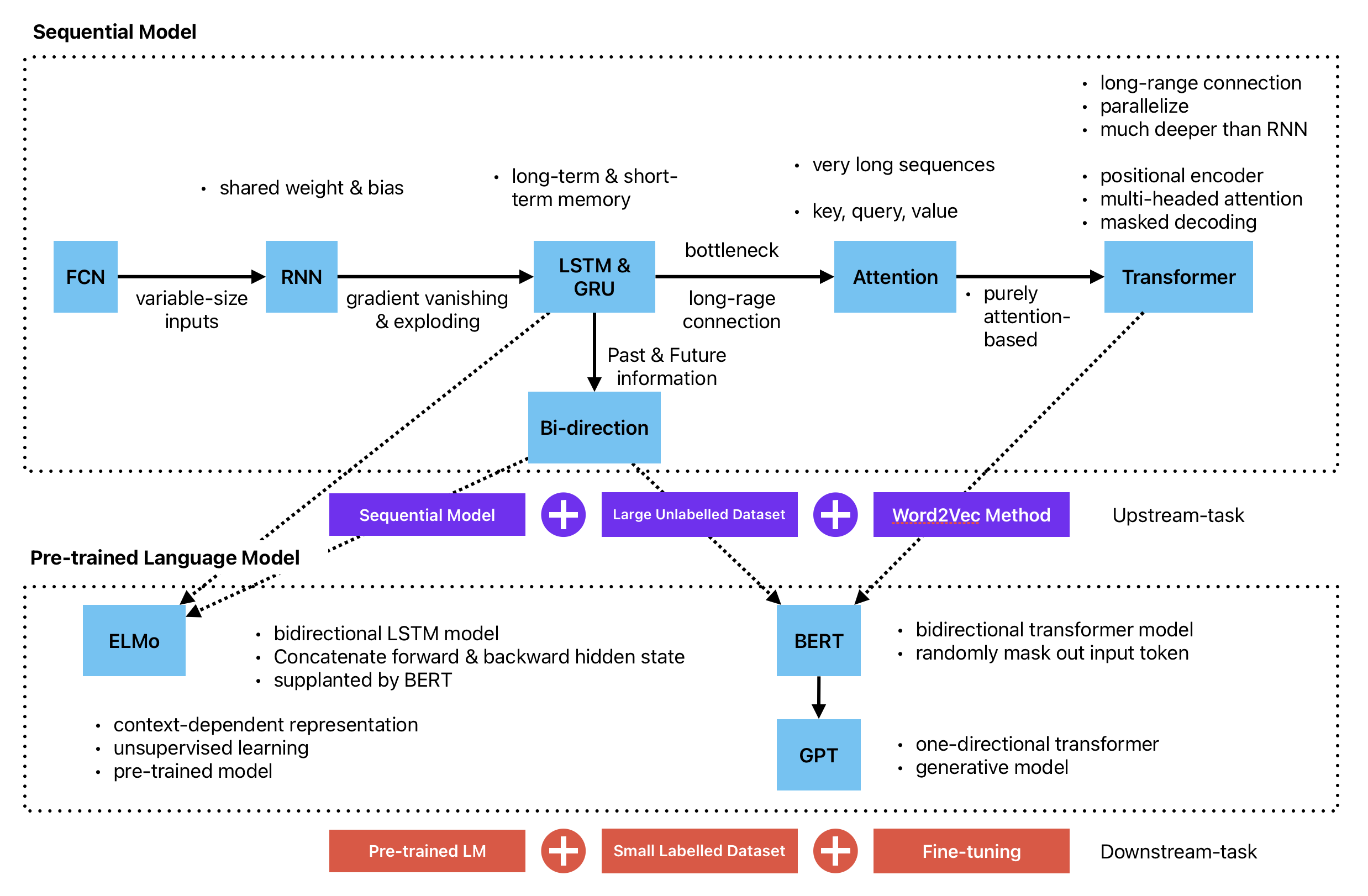
아래 그림은 개략적인 흐름을 나타낸 것이다. cs182 강의의 장점은 스토리텔링에 있다고 생각한다. 우선은 RNN 계열부터 Transformer까지 모델의 구조적인 부분에 대한 부분을 다룬다. 각 모델 별로 어떤 문제를 해결하기 위한 것인지 어떤 한계점이 있는 것인지 설명되어서 이해하기 좋은 것 같다. 예를 들면 naive RNN은 gradient vanishing이나 exploding 현상이 발생하기 때문에 이러한 한계를 보완하기 위해 LSTM 구조를 사용하게 되었다. Attention은 LSTM의 bottleneck으로 인한 long-range connection 문제를 해결하기 위한 구조이다. 마지막으로 Transformer로 RNN계열의 특징상 보다 깊게 쌓을 수 없는 문제를 해결하기 위해 순수한 Attention 기반의 구조를 만들었다.
그 이후에는 구조들을 기반으로 하여 방대한 양의 무가치해 보이는 데이터를 활용하는 방법에 대한 설명을 진행되었다. 기존에는 학습을 위한 데이터를 별도로 구성하였다. 이런 방식으로 데이터를 쌓는 것은 한계가 있으며, 비효율적이다. 온라인에는 이미 엄청난 양의 데이터가 쌓여있어 이를 활용하는 것이 pre-training의 목적이다. pre-training은 upstream task라고도 불린다. 언어와 관련해서 upstream task는 단어나 문장 같은 표현 자체를 익히는 것을 의미한다(representation learning). 어떻게 하면 이런 학습이 가능한 지에 대해서 먼저 배운다. 이후에는 앞서 배운 attention과 transformer 구조 등을 이용해 pre-trained 모델을 만든 것들에 대한 특징과 장단점들에 대해 배우게 된다.
- Sequential Model Structure
- naive RNN
- LSTM (상세히 설명) & GRU (거의 안다루고 넘어감)
- Attention
- (purely attention-based) Transformer
- Pre-trained Model
- Representation Learning
- ELMo
- BERT
-
GPT
RNN 계열의 알고리즘
RNN 구조
우선 RNN 구조는 왜 필요한 것일까? 실생활에서는 입력 변수의 길이가 서로 다른 데이터가 더 일반적인 것 같다. 인터넷에 작성된 글이나 동영상, 음악 등 대부분 길이가 고정되어 있지 않다. 이러한 데이터를 활용하기 위해서는 어떻게 해야될까? 인풋 길이와 상관없이 적용가능한 구조를 만들어야할 것이다. RNN은 개념적으로 입력 데이터 길이에 맞춰서 layer를 추가해주는 구조이다. 이렇게 하면 발생되는 문제점이 layer의 개수가 증가하며 이에 따라 학습이 필요한 weight와 bias 또한 같이 증가하게 된다. 이런 문제는 추가되는 layer의 가중치(weight)와 편향(bias)를 공유하도록 하여 해결하였다. 공유된 weight와 bias를 이용하면 입력의 길이와 상관없이 사용할 수 있게 된다. 마찬가지로 output에 대해서도 길이를 원하는 만큼 조절할 수 있게 된다.
LSTM 구조
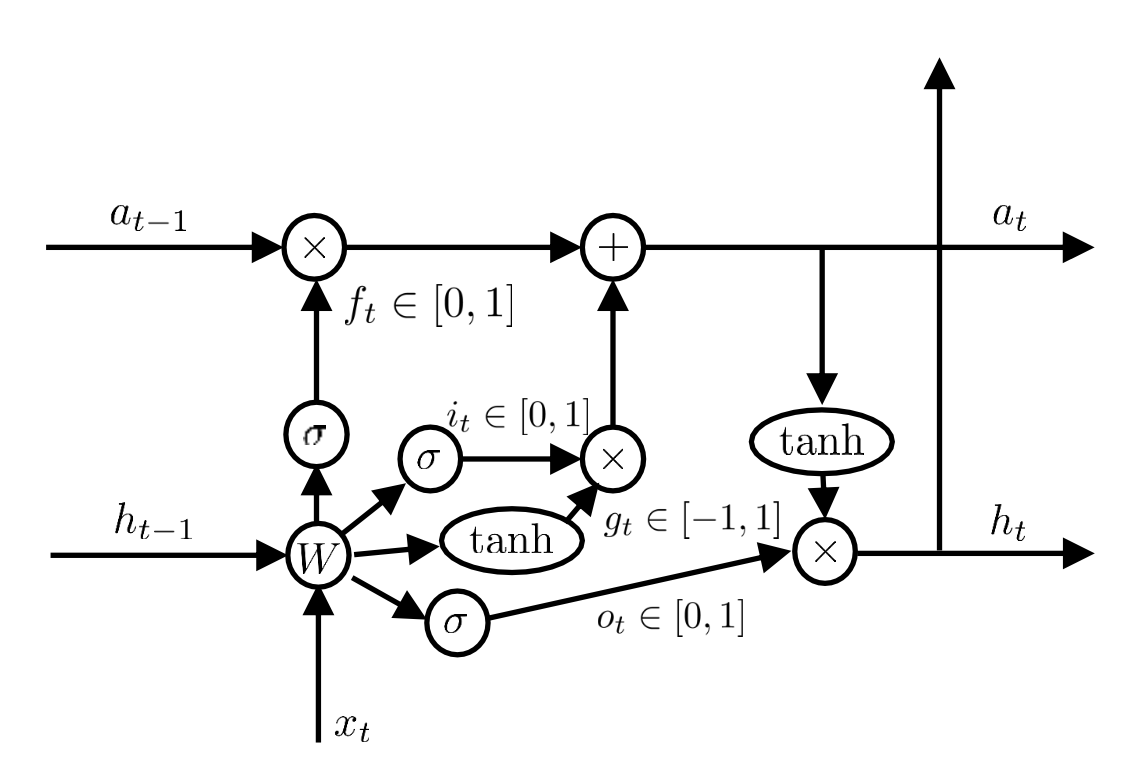 위의 그림과 같이 구성하게 된다. 이 그림은 정말 많이 봐온 그림이긴 하지만 제대로 이해하기 어려웠다. 각각의 게이트가 가지는 의미를 알고나게 되니, 조금 더 이해가 쉬운 것 같다. 는 cell state 또는 long-term memory라고 불리며 는 hidden state 또는 short-term memory라고 부른다. hidden state는 매 스텝마다 cell state와 곱해져서 계산 되기 때문에 비교적 빠르게 업데이트 된다. cell state의 경우에는 , , 등 복잡한 계산을 거친다. 의 경우에는 이전 단계의 hidden state 그리고 현재의 input 가 곱해져 과거 상태를 얼마나 기억할 지에 대해서 결정한다. 그리고 는 현재 상태를 기억할 지에 대한 결정, 는 얼마나 반영 시킬 지를 각각 결정하게 된다. 이런 방식으로 cell state는 천천히 변경되기 때문에 long-term memory라고 불리게 된다.
LSTM은 naive RNN에 비해서 매우 월등하게 복잡한 구조이지만, 성능이 우수하다. GRU의 경우에는 LSTM 유사한 아이디어를 가지고, 가볍게 작성된 모델이다. GRU가 대체로 연산 속도가 LSTM에 비해서 우수하고 성능은 유사하거나 다소 떨어진다. 일반적으로 RNN이라고 하면 naive RNN을 의미하는 경우보다는 LSTM이나 GRU를 의미하는 것으로 보인다 그래서 naive RNN라고 용어를 구별해서 사용하는 듯 하다.
위의 그림과 같이 구성하게 된다. 이 그림은 정말 많이 봐온 그림이긴 하지만 제대로 이해하기 어려웠다. 각각의 게이트가 가지는 의미를 알고나게 되니, 조금 더 이해가 쉬운 것 같다. 는 cell state 또는 long-term memory라고 불리며 는 hidden state 또는 short-term memory라고 부른다. hidden state는 매 스텝마다 cell state와 곱해져서 계산 되기 때문에 비교적 빠르게 업데이트 된다. cell state의 경우에는 , , 등 복잡한 계산을 거친다. 의 경우에는 이전 단계의 hidden state 그리고 현재의 input 가 곱해져 과거 상태를 얼마나 기억할 지에 대해서 결정한다. 그리고 는 현재 상태를 기억할 지에 대한 결정, 는 얼마나 반영 시킬 지를 각각 결정하게 된다. 이런 방식으로 cell state는 천천히 변경되기 때문에 long-term memory라고 불리게 된다.
LSTM은 naive RNN에 비해서 매우 월등하게 복잡한 구조이지만, 성능이 우수하다. GRU의 경우에는 LSTM 유사한 아이디어를 가지고, 가볍게 작성된 모델이다. GRU가 대체로 연산 속도가 LSTM에 비해서 우수하고 성능은 유사하거나 다소 떨어진다. 일반적으로 RNN이라고 하면 naive RNN을 의미하는 경우보다는 LSTM이나 GRU를 의미하는 것으로 보인다 그래서 naive RNN라고 용어를 구별해서 사용하는 듯 하다.아래 링크에 블로그에서 보다 상세하게 잘 작성되어있다. LSTM, GRU 이론 및 개념 참조 링크
Attention 구조
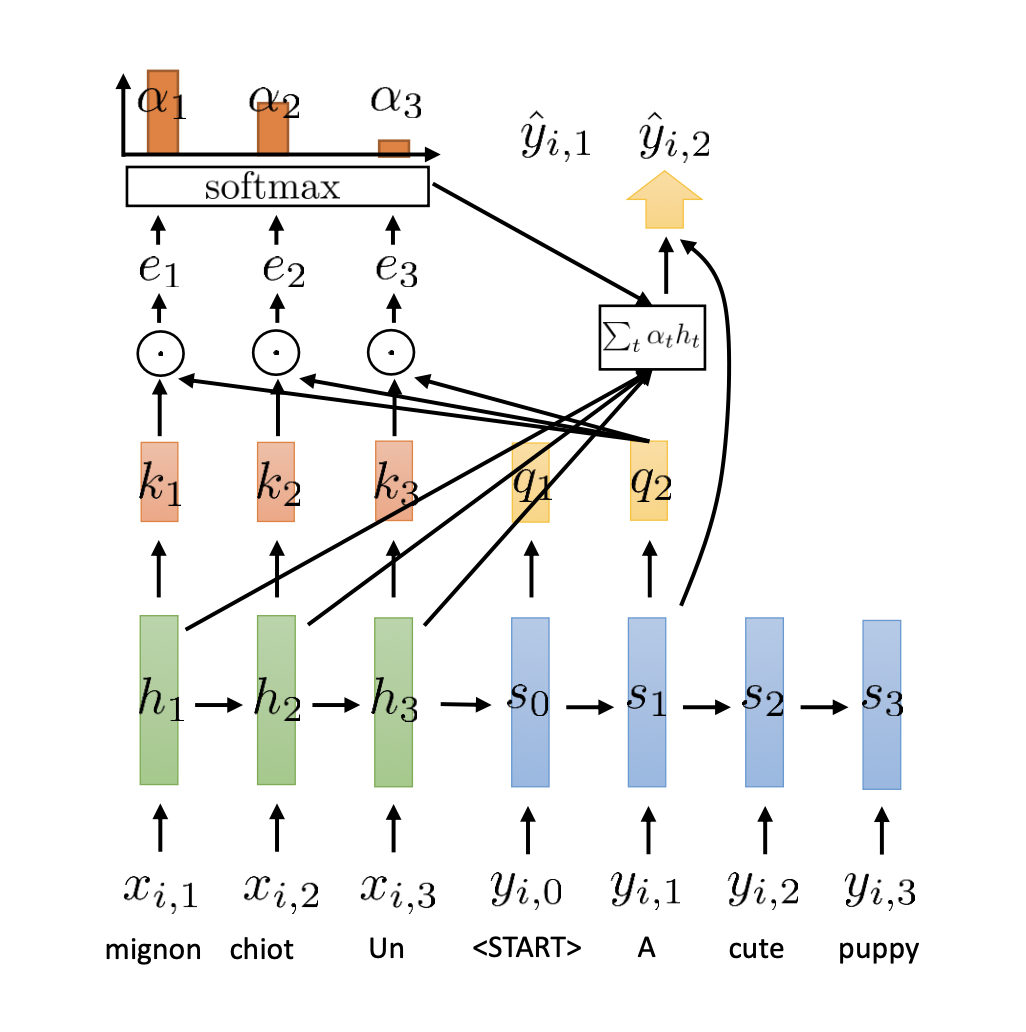
attention과 관련해서는 아래 블로그 내용이 이해가 쉬웠다. https://shyu0522.tistory.com/12
Transformer 구조
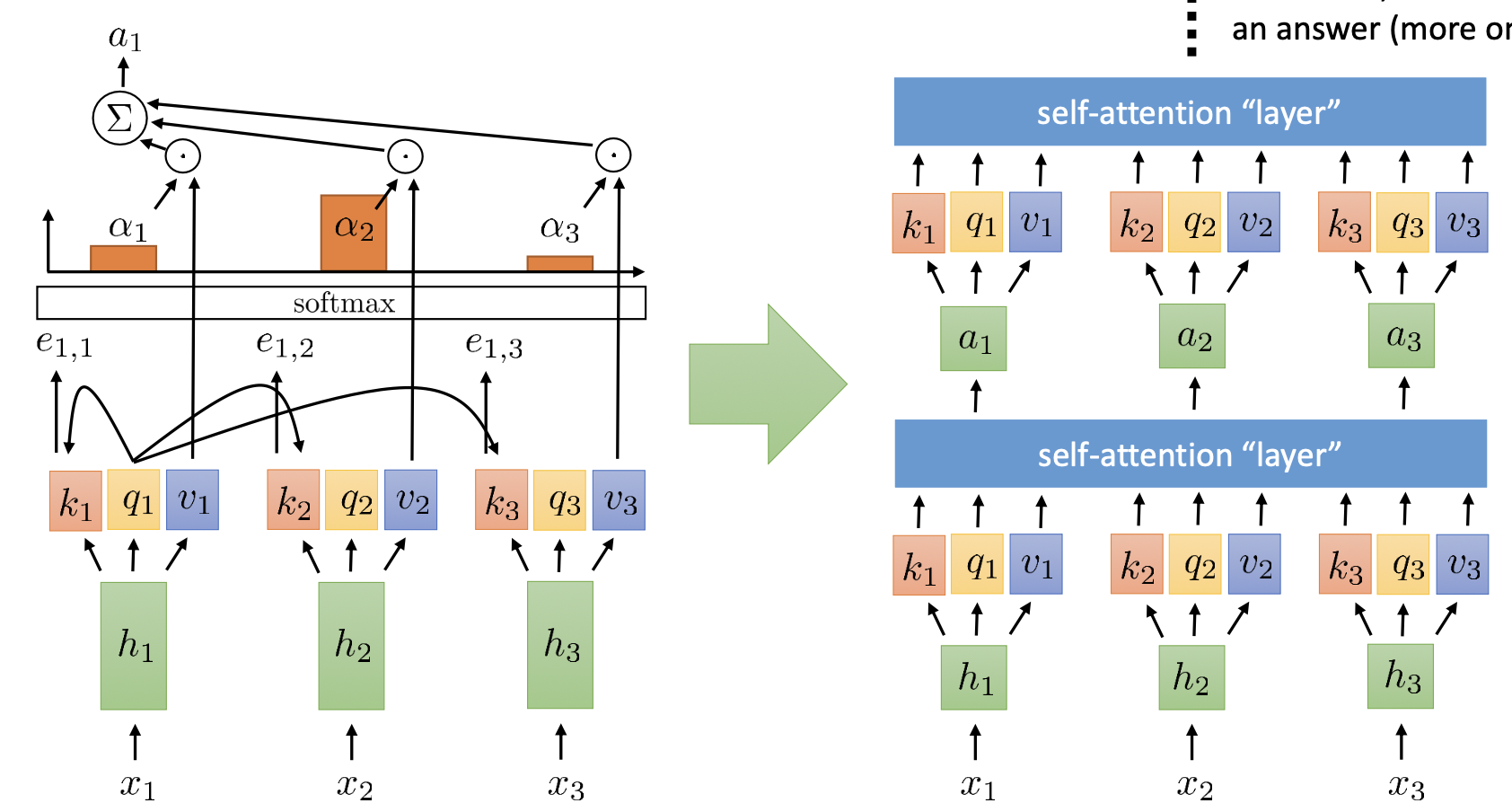 self-attention 구조는 transformer를 만들기 위한 근간이 되고 추가적으로 4가지 요소가 필요하다.
self-attention 구조는 transformer를 만들기 위한 근간이 되고 추가적으로 4가지 요소가 필요하다.- Positional encoding: 위와 같은 구조는 입력 순서와 상관없이 동일한 값이 나오게 되므로, 위치정보를 같이 입력해주어야할 필요가 있음
- Multi-headed attention: 다양한 종속성에 대해서 학습하기 위해 사용.
- Adding nonlinearities: 각 레이어는 선형이기 때문에 비선형성 추가
- Masked decoding: 다음 스텝의 값을 참조하는 것을 방지하기 위해 사용
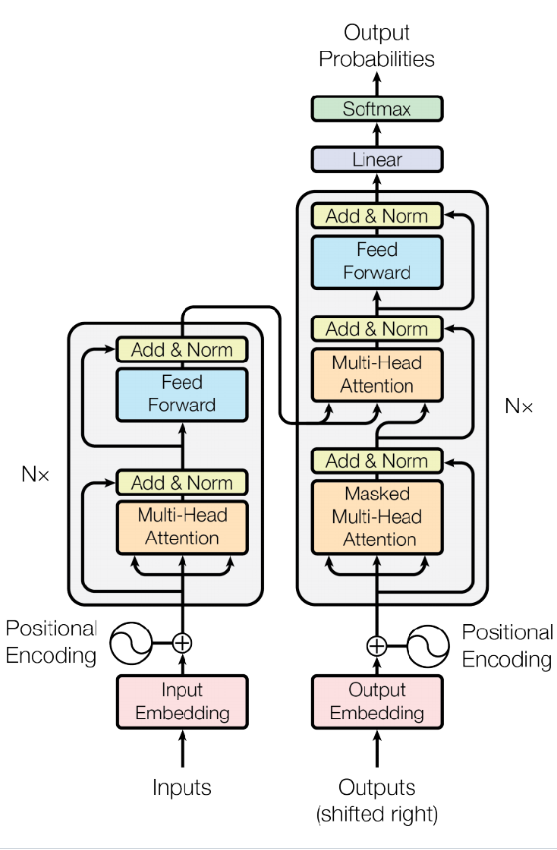
전체적인 요약
Sequential Model에 이용되는 여러 가지 구조들에 대해 알 수 있었다. 각 구조가 나온 배경들과 개선사항들을 알게 되니 조금 더 깊은 이해를 할 수 있었다. 특히 transformer 구조는 엄청나게 복잡하여 공부를 시작하면 겁부터 나게 되는데 차근차근 구조 하나마다 이해를 할 수 있었다. 매번 자료를 찾아볼 때 마다 이해했다는 느낌을 거의 받지 못했었는데 처음으로 이해를 한 것 같은 기분이 들었다.
Pre-trained model
Representation Learning
 기본적으로 표현을 학습하는 것은 단어나 문장 등을 벡터로 변환하는 것이다. 주변 단어들을 통해 특정 단어가 나올 확률을 계산하는 방식 등을 이용한다. 임베딩이 잘 된 경우에는 유사한 단어까지 모이거나 대수적인 관계를 갖게 된다. 예를 들어 "왕 + 여자 = 왕비"와 같은 연산이 가능하게 된다. 딥러닝 모델과 방대한 양의 라벨링 되지 않은 데이터를 활용해 이러한 표현을 학습하는 것을 사전 학습된 언어 모델(pre-trained language model)이라고 한다. 이러한 언어의 표현을 배우는 과정을 upstream task라고 한다.
사전 학습 모델을 이용해 질의 응답이나 감정 분석 같은 원하는 작업을 하는 것을 downstream task라고 한다. 딥러닝 모델 학습에는 방대한 양의 데이터가 필요하나 사전 학습된 모형을 사용하면 적응 양의 데이터를 이용해서 우수한 성능의 downstream task를 수행하도록 학습할 수 있다.
기본적으로 표현을 학습하는 것은 단어나 문장 등을 벡터로 변환하는 것이다. 주변 단어들을 통해 특정 단어가 나올 확률을 계산하는 방식 등을 이용한다. 임베딩이 잘 된 경우에는 유사한 단어까지 모이거나 대수적인 관계를 갖게 된다. 예를 들어 "왕 + 여자 = 왕비"와 같은 연산이 가능하게 된다. 딥러닝 모델과 방대한 양의 라벨링 되지 않은 데이터를 활용해 이러한 표현을 학습하는 것을 사전 학습된 언어 모델(pre-trained language model)이라고 한다. 이러한 언어의 표현을 배우는 과정을 upstream task라고 한다.
사전 학습 모델을 이용해 질의 응답이나 감정 분석 같은 원하는 작업을 하는 것을 downstream task라고 한다. 딥러닝 모델 학습에는 방대한 양의 데이터가 필요하나 사전 학습된 모형을 사용하면 적응 양의 데이터를 이용해서 우수한 성능의 downstream task를 수행하도록 학습할 수 있다.ELMo
ELMo는 기본이 되는 구조로 Bidirectional-LSTM을 사용하고 있으며, 빈 단어를 예측하는 것을 목적으로 모델을 학습한다. 순방향으로 예측할 때 사용하는 hidden state와 역방향으로 사용되는 hidden state를 결합하여 사용한다. 학습가능한 매개변수를 두어 사용할 수도 있다. ELMo의 경우 LSTM이 가지는 한계 때문에 그런지 잘 사용되지는 않는 듯 하다.
BERT
Transformer 구조를 이용해서 Representation Learning에 사용하는 방법이다. 표현은 두 가지를 목적으로 학습하게 된다. 문장의 순서를 맞추는 것과 랜덤하게 비워져 있는 단어를 맞추는 것이다. 데이터 셋은 두 개의 문장으로 구성된다. 랜덤하게 50%의 데이터 셋은 문장의 순서를 바꾼다. BERT 모델은 문장의 순서가 바뀌어 있는 지 예측하게 되고, 이를 통해 문장 단위의 표현을 학습 할 수 있게 된다. 또 15% 비율에 해당하는 단어를 가리게 되는데, 이 단어를 복원하는 것이 다른 하나의 목적이다. 이를 통해서 문맥이 고려된 단어의 표현을 학습할 수 있게 된다. BERT는 ELMo와 같이 양방향의 정보를 함께 사용하는 모형이다. 따라서, 생성형 모델로의 활용은 어렵다.
GPT
GPT의 경우 BERT와 유사하게 Transformer 구조로 구성되어 있지만, 양방향의 정보를 활용하는 것이 아닌 순방향으로 단어를 예측하는 구조이다. 따라서, 생성형 모델에도 사용 가능하다는 장점이 있다. CS182 강의 내에서 GPT에 대한 상세한 부분을 다루지는 않았다. BERT가 GPT에 비해 표현을 배우는 부분에서는 더 좋을수도 있을 것 같다. 그렇지만 생성형 모형으로 활용가능하다는 점에서 GPT의 장점이 압도적인 것 같다.
전체적인 소감
하나의 글에 너무 많은 내용을 담은 것 같다. 해당 내용으로 강의를 듣고 스터디에서 발표한 지는 거의 한달이 다 되어가는 것 같다. 그 시기부터 계속 작성했는데 이제 완성된 걸보면 글 단위를 조금 더 나눌 필요가 있어보인다. 공부한 내용을 다시 복습하는 차원에서 많은 도움이 된 것 같다. 다음 번에 작성할 때는 조금 더 작은 단위로 내용을 작성해야겠다.
데이터·AI 엔지니어. RAG·LLM 인프라와 시계열, 그리고 개발하며 겪은 것들을 기록합니다. 여행과 잡다한 호기심도 함께.